Vivadoのプロジェクトの作成方法
はじめに
そういえば,Vivadoを初めて触った時にプロジェクトの作り方が難しくて詰まったという記憶から,こういう記事あるといいのかもなあという気持ちで書いていますが,間違っていそうなので誰にも読まれないでほしいです.
Digilentのボードを使っている場合は,詳しくDigilentのサイトに載っています.
自分の環境
- Windows10
- Vivado 2020.2
です.
また,当然ですがIntel製のFPGAを使う際には,それ用のツールがあって,Vivadoでいろいろ行うのは無理なような気がします.
ステップ1:自分のボードの情報を入れる
自分のボードの情報を入れましょう.
私は,Digilentのボードしか使ったことないのでその説明のみを書きます.Vivado Board Files for Digilent FPGA Boardsからフォルダをダウンロードして,自分のボードに合うフォルダを見つけましょう.
Microblazeを使う場合は,
Important! At the time of writing, if using a Spartan or Artix-based board for Microblaze designs, it is recommended to use an alternate version of the board files which better support the DDR memory present on some boards. This version of the board files can be downloaded via this link: Microblaze-MIG.zip. Instructions for setting up DDR memory in a Microblaze design using these files can be found in Getting Started with Vivado and Vitis for Baremetal Software Projects.
と書いてあります.気を付けましょう.
探してこれたら,そのフォルダを
C:/Xilinx/Vivado/<version>/data/boards/board_filesというディレクトリに貼り付けます.
自分の環境では,次のようになっています.

ステップ2:Vivadoを起動する

上のようなアイコンをダブルクリックしましょう. 最近のソフトウェアと違って,起動に時間がかかります.
複数回ダブルクリックを行うと,行った数だけVivadoが起動される点には気を付けましょう.
ステップ3: プロジェクトを作る
Quick Start->Create Projectを押します.

Nextを選択します.
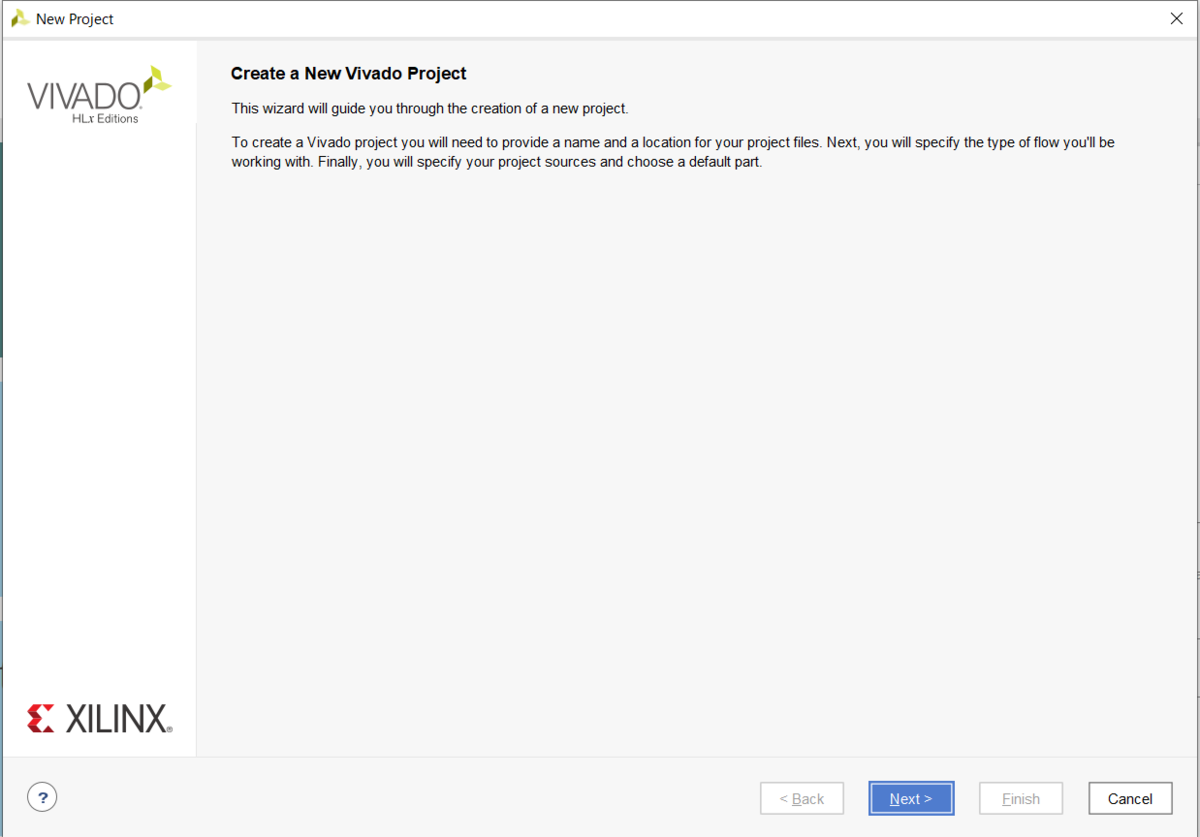
自分のお好みの場所を選択して,プロジェクトの名前を決めましょう.Create project subdirectoryはよくわからないですが,チェックを入れておけば,サブディレクトリに作ってくれるらしいです.そして,Nextを押します.
ところで,Vivadoは繊細なソフトウェアなので空白があるようなディレクトリにプロジェクトを制作すると,動かない場合があるので注意してください.
また,内部は絶対パスで管理するのでプロジェクトを移動させると動かなくなる場合があります.

RTL Projectを選ぶ場合が主な用途だと思います.
Do not specify sources at this timeにチェックを入れるとファイル追加の画面がスキップされます.今回はファイルを追加しないので,チェックを入れておきます.

ファイルを追加する画面が出てきた場合は,そのままNextを押します.そうでない場合は下のような画面になるはずです.これは,ボードを選択する画面です.
わかりにくいのですが,上の真ん中ほどにあるBoards というタブをクリックすると,2つ下の画像のようになります.
ここで自分のボードを選択すると青色になります.


最後に次のようなウィンドウになると思います.これでFinishを押すと完成です. おめでとうございます.

おわりに
おそらく回路を記述する記事も書くと思います.
Node.jsを使用するために
はじめに
本当は、Qiitaとかに投稿しようか迷ったけど、あんまり有用なことは書けないなと思って、こっちに書くことにした。*1
知っておくべきこと
Node.jsは、ブラウザのV8というJavaScriptエンジンを取ってきたものになります。
したがって、これを入れておくことでブラウザから離れたところであってもJavaScriptを使うことができます。これにより、フロントのブラウザからバックのサーバまで1つの言語で書くことができます。
Node.jsのバージョンは、a.b.cという表記がされaが偶数であるバージョンは安定版と呼ばれ、メンテナンスを主にしたバージョンです。したがって、このバージョンを使うのがメインになります。
Node.jsはバージョン更新がとても速いです。よって、まず、Node.jsのバージョンを管理するアプリケーションをインストールするところから始めることになります。
Windows
まず、Windowsに直接Node.jsのバージョンマネージャを入れることをお勧めしないです。というのは、バージョンマネージャの更新は活発ではなく、バグを踏む可能性やNode.jsの新しいバージョンを入れるのに手間取る可能性が高いです。*2
WindowsでNode.jsのバージョンマネージャの選択肢は、いろいろありますが、私が知っているのは、次の2つです。
- nvm for windows
- nodist
個人的には、nvm for windowsをお勧めします。
nvm for windowsの入れ方
インストーラを取ってきましょう。 インストーラを起動させてポチポチすれば完了です。
nvm for windowsでNode.jsを入れる
わかる人は、上のGithubのREADMEを見て入れましょう。*3
管理者権限を持った状態で、次のコマンドを入れるとよいです。
nvm install <version> nvm use -g <version>
とすると、グローバル環境でNode.jsが入ります。
node -v
で今入っているNode.jsのバージョンがわかります。
macOS
Macの人は、まずbrewを入れましょう。そして、brewにNode.jsのバージョンマネージャのバージョン管理をさせます。
私が知っているNode.jsのバージョンマネージャはnodenvのみです。ほかにはnvmというものがあるみたいです。anyenvでnodenvやrbenvやpyenvといったenv系のバージョンマネージャが管理できますとだけ書いておきます。*4
わかる人は、nodenvのレポジトリを見に行きましょう。 次にnodenvでNode.jsを入れましょう。わかる人は、nodenvのレポジトリを見に行きましょう。
brewでnodenvを入れる。
brew install nodenv
次に、シェルの設定ファイルに次を書き込みます。これはシェルの立ち上げのたびに、nodenvの初期化をするコマンドですね。
eval "$(nodenv init -)"
そして、シェルを立ち上げなおします。
レポジトリのREADMEを見ると、次のコマンドでインストールできたかの確認できます。
curl -fsSL https://github.com/nodenv/nodenv-installer/raw/master/bin/nodenv-doctor | bash
以上でnodenvが入れ終わりました。次にnodenvでNode.jsを入れましょう。
nodenv install <version> nodenv global <version>
これでグローバル環境にNode.jsが入ります。
LinuxとWindows(wsl)
Windows持っている人はwsl環境で行うのがおすすめです。
私が知っているNode.jsのバージョンマネージャはnodenvのみです。ほかにはnvmというものがあるみたいです。
ただ、Linuxの環境では、anyenvでnodenv、pyenv、rbenvといったほかの言語のバージョン管理できるみたいなのでanyenvを入れるところから入ります。
つまり、バージョンマネージャのバージョンマネージャを入れるということです。気に入らなければ、apt install nodenvでnodenvを入れられます。
anyenvを入れます。anyenvのレポジトリのREADMEを見ましょう。
入れ終えたら、
anyenv install nodenv
として、nodenvを入れましょう。
次に、シェルの設定ファイルに次を書き込みます。これはシェルの立ち上げのたびに、nodenvの初期化をするコマンドですね。
eval "$(nodenv init -)"
そして、シェルを立ち上げなおします。
レポジトリのREADMEを見ると、次のコマンドでインストールできたかの確認できます。
curl -fsSL https://github.com/nodenv/nodenv-installer/raw/master/bin/nodenv-doctor | bash
以上でnodenvが入れ終わりました。次にnodenvでNode.jsを入れましょう。
nodenv install <version> nodenv global <version>
これでグローバル環境にNode.jsが入ります。
おわりに
これでNode.jsを使えますね






CPS変換について
はじめに
ISer Advent Calendar 2021 - Adventarの記事です.
まじめに書きたいなと思います。
CPSとは
CPSは、Continuation-Passing Styleの頭文字をとって名付けられています。これは継続と呼ばれるものを使ったプログラムの書き方の1つです。継続は、「今行う計算の続きの計算」を表していると考えられます。そして、CPS変換は、通常の書き方をCPSに変換することを指します。
とりあえず、JavaScriptでの例を見てみたいと思います。
次の処理を行うことを考えます。
- 引数
kに1を足す。 - 上の結果を2倍する。
- 上の結果から1引く。
- 上の結果を表示する。
ここでは上の処理一つ一つを関数にして、書いてみたいと思います。
function add1(v) { return v + 1; } function times2(v) { return 2*v; } function minus1(v) { return v - 1; } let initial_value = 1; console.log(minus1(times2(add1(initial_value))));
これをCPSに変換すると次のようになります。
function add1(k) { return function(r) { return k(r + 1); } } function times2(k) { return function(r) { return k(2*r); } } function minus1(k) { return function(r) { return k(r - 1); } } let inital_value = 1; let something = add1(times2(minus1(function (r) { console.log(r); })));
上のadd1やdoubleといった関数に渡される引数kはすべて継続です。そして、最後の関数呼び出しが重要です。呼び出し部分だけを抜き出すと、
add1(times(minus1(function (r) { console.log(r); })))
となります。これをじっくりと観察しましょう!
内側から見ていくと、minus1に引数を受け取って表示する関数を渡しています。継続は「今行う計算の続きの計算」であることを思い出せば、これはminus1の後に値を表示するという継続を渡していることになります。
minus1(function (r) { console.log(r); })
つぎは、times2にminus1(hoge)を渡していますね。もう1度、継続は「今行う計算の続きの計算」であることを思い出せば、times2の後にminus1(hoge)を行うのでtimes2の継続はminus1になります。
times(minus1(function (r) { console.log(r); }))
さらに、add1にtimes2(minus1(function(r) { console.log(r); } ))を渡しています。これはadd1した後にtimes2(minus1(function(r) { console.log(r); } ))というこれから行う処理を渡しています。
add1(times(minus1(function (r) { console.log(r); })))
さて、最後にすべての返り値であるsomethingとは何でしょうか?
これは、これから行う処理と考えられます。よって、このsomethingを継続としてほかの処理に渡していくことができます。いまは計算を実際に行って、結果を表示する処理まで行いたいです。そうするためには、この関数を評価すればいいことがわかります。そうすると上の1~4までの計算が実際に行われます!
something(1);
CPS変換とコールバック関数
さて、上のような継続はどこかで見たことはないですか?Promiseを扱ったことがある人ならわかると思います。
そうです!コールバック関数*1です。コールバック関数は、呼び出した関数の処理が終わったら呼び出す関数のことですが、言い換えれば「今行う計算の続きの計算」です。
CPS変換と末尾再帰最適化
今度は上で述べたcallbackを意識しながら、再帰関数で書いた階乗のCPS変換を見ていきましょう。
通常は、階乗の計算は次のようになります。
function fact (n) { if (n < 1) { return 1; } else { return n * fact (n-1); } }
一方、継続を用いた書き方に直すと次のようになっています。
function fact_cps (n, callback) { if (n < 1) { return callback(1); } else { return fact_cps (n-1, function (r) { return callback(n*r); }) } }
実際に使うには、次のようにすればよいです。
fact_cps(4, function(v) { console.log(v); });
ここで末尾再帰最適化の話をしたいと思います。 末尾再帰最適化とは、再帰関数において最後に1度だけ関数呼び出しが行われ、処理が終了するように関数を最適化を行うことです。 こうすることで関数呼び出しのためにスタックを保持する必要がなくなり、スタックオーバーフローが起きにくくなります。
通常の再帰関数では、n * fact(n - 1)の部分で関数呼び出し後に掛け算が行われます。
一方、上のCPS変換後の関数は、最後にfact_cpsの呼び出しが行われて、末尾呼び出しになっています。*2
主張は、CPS変換を理解すると末尾再帰最適化がしやすくなる!ということです。
しかし、上のfact_cpsに掛け算をする関数渡すだけです。関数を渡すことは無駄が多いです。これを何とかできないでしょうか?
実は次のことに注意すると、掛け算する関数を整数と同一視することができます。具体的には次のようになります。
ここで、はモノイドであり、
はモノイド同型になる。*3
合成が、整数の掛け算になるので関数の合成は掛け算であり、関数を1つの整数で表すことができます。
よって、次のようになります。
function fact_cps2 (n, v) { if (n < 1) { return v*1; } else { return fact_cps2 (n-1, v*n) } }
次は、末尾再帰最適化が難しいフィボナッチ関数についてみていきたいと思います。
function fib(n) { if(n < 2) { return 1; } else { return fib(n-1)+fib(n-2); } }
まず、最後にfib(n-1)+fib(n-2)としています。これは、最後は、足し算の処理で終わっており、末尾呼び出しになっていません。では、CPS変換を行いたいと思います。
function fib_cps(n, callback) { if (n < 3) { return callback(1); } else { return fib_cps(n - 1, function (a) { return fib_cps(n - 2, function (b) { return callback(a + b); }) }) } }
よく見れば、すべての関数が末尾呼び出しになっています。つまり、CPS変換をすると、自然に末尾呼び出しが可能になる!ということです。
おわりに
あんまり理解していないことを記事にするのは、つらいです。*4
tf-idfについて
これは、ISer Advent Calendar 2020 14日目の記事として書かれました。
はじめに
tf-idfについて知っていますか?
知っています?では、おそらくこの記事の情報量は0です。 advent calendar8日目の記事を見て、休憩してください。 また、英語を読むのに抵抗がない人は、wikipediaのtf-idfにいろいろ書いてあって、ここに書いてあるより詳しいので読んでみてください。
tf-idfとは
tf-idfは、文章の集合に対して、ある文章の単語の重要度を数値化する際の1つの方法です。
tfは単語の出現頻度(term flequecy)、idfは単語の逆文章頻度(Inverse Document Frequency) です。 これの二つの掛け算をtf-idfすることで、ある文章中の出現する単語の重要度を評価できます。この数値を使うことで、検索等に用いることができます。
より詳細に
定義
使う記号を定めます。
その他集合にバーを付けたら、要素の数とします。
TFについて
まずは、素朴なTFです。この値は、文章と単語
を引数に受け取ります。
ざっくりというと、全体で、ある単語がどれぐらい
に表れているかという数値になり、term flequencyになります。
IDFについて
以下のように定義できます。単語に対して定まります。
TFだけで、単語の重要性が図れそうに思いますが、よく出てくる単語(例:「まず」)の価値は低いと考えられ、めったに出てこない単語(例:「逆文章頻度」)は価値が高い単語と考えられます。よって、以上のIDFが必要になります。
また、単語によっては分母が0になったりするので、分母分子に1を足したりしている定義もあります。
tf-idf
tfとidfをかけるだけです。
そのほかの定義
頑張って書こうか悩んだんですが、疲れているので止めました。 日本語では、yukinoiさんのブログにいろいろ並んでいました。
英語の記事は豊富でした。
tf-idfを使ってできること
cos類似度
文章間での類似度を計算することができます。これは、単語1つ1つを1次元と見て、を文章
の単語
方向の大きさとした時の、文章ベクトルの内積
から定義することができます。
すなわち、以下のように定義できます。
検索機能
他には簡単な検索機能を実装することができます。おそらく手順としては以下のようになります。
前準備
- 文章集合を用意する。この文章1つが検索の対象です。
- 必要であれば、文章中の単語を整形しておく。(半角カナを全角カナに変換する等)
- 文章それぞれを形態素解析し、単語に分割する。日本語であれば、これは、MeCabを使えばできます。書店でいろいろ見ましたが、pythonからどうやら使えるみたいです。
インストールの際には、文字コードに気を付ける必要があります。コマンドプロンプトのデフォルトはshift_jisです。pythonから使う場合はutf-8がいいと思います。 - 文章の単語ごとにtf-idfを計算し、保存しておく。
検索の段階
- 検索のキーワードを形態素解析する
- ある文章における、キーワードの単語それぞれのtf-idfを使い、文章それぞれのスコアを計算する。
単純に加算するなら以下のようになります。
- 文章のスコアをソートし、検索結果として出す。
他には、cos類似度を使い、検索のスコアを最後にいじるともう少し精度がよくなるかもしれません。
さいごに
hatenaブログでのtex打ちはだるかった。
はじめてのブログ
初めてのブログです。