大学のスポーツ・トレーニング施設の紹介
はじめに
この記事はN代アドベントカレンダー 12/15の記事として書かれました。
大学には御殿下記念館と呼ばれるジムが本郷キャンパスにあります。 この施設には、トレーニング室やプール、体育館があり、その料金もその辺のジムに通うより安いです。 この記事は、一部の施設についてどう利用するのかについて紹介しようと思います。 詳しいことは、御殿下記念館のウェブページ、パンフレットが存在しているので、そちらを参照してください。
今後、本郷キャンパスに通われる方、あるいは大学を卒業した方であっても安く施設を利用が可能であるため、ぜひ利用しましょう!
行えること
以下のような施設が存在し、そこでいろいろな運動を行うことができます。 基本料金としての入館料を払うだけですべて行うことが可能です。 また、バスケットボール、フットサルボール、バトミントンラケット(有料)の貸し出しが可能です。
ここに挙げた以外の情報として、ロッカーにはシャワーとサウナがついています。
現在の開館時間は以下のようになっています。

今回は、自分がよく利用するトレーニング室の利用、プールの利用の説明に絞ります。
施設利用の流れ
大まかには次のようになります。
- 御殿下の入り口で入館料を払い、利用のための情報を記入します。
- ロッカーのカギを受け取り、ロッカーに向かう
- ロッカーで着替え、目的の施設に行き、運動を行う。
- 終わり次第ロッカーで着替え、受付でロッカーのカギを返す。
入館料は現在時点で下の画像のようになっています。

ここで1年パス、半年パスは、それぞれ購入すると1年間、半年間入館料を払う必要や情報の記入が省略されます。 このパスは、運動会窓口で顔写真と学生証の提示で購入可能です。御殿下受付では購入できないので気を付けましょう
また、卒業生は料金体系が変わり、また運動会員に事前になっておく必要があります。これも運動会窓口で手続きが可能です。
プールについて
プールは、帽子と水着があれば利用が可能です。 プールには完泳者向けのコースが4コース、歩行専用コースが1コース、自由コースが1コースあります。
平日、土曜の夕方から混み始める印象があるので、昼間に行くといいと思います。
トレーニング室について
トレーニング室利用には事前に登録が必要です。登録しなくても利用可能ですが、500円追加でかかります。 登録は、講習会への参加で可能です。 講習会は定期的に開催しているので予約していきましょう。1500円かかります。
トレーニング室には、各種筋トレ用のマシン、ランニングマシン、またウェイトリフティング等の本格的な筋トレも可能です。 また、筋トレ用のダンベル、腹筋ローラー等の器具も充実しています。
平日の夕方からランニングマシンやウェイトリフティングのエリアがかなり混み始めるので、空いている時間に行きたい場合はこれも昼間行くといいと思います。
おわりに
運動しよう!!!!!
Tampermonkeyでslideshareのアレな広告を回避するユーザスクリプト作成
はじめに
この記事はN代アドベントカレンダー 12/5の記事です。
あるサイトにアクセスした際、「ボタンを追加等をしカスタマイズしたいけど、拡張機能を作るほどでもないな」というときがあると思います。 このような際には、ブラウザの開発者機能を開いて、JavaScriptを書いてDOMを操作するということをすると思います。 Tampermonkeyは、そのようなユーザスクリプトを保存しておいてアクセスした際に勝手に実行するというブラウザ拡張になります。
今回は、slideshareのアレな感じを回避するユーザスクリプトを実際に作成してみることを通じて、Tampermonkeyの紹介を行いたいと思います。
やりたいこと
slideshareの画面を見るとこのように広告がアレな感じです。

しかし、実はslideshareの埋め込みリンクから見ると、これら広告を回避することが可能です。(え?)

今回はslideshareにおいて、埋め込みスライドへ飛べるようなボタンを、スライドを参照した際に追加できるようにします。 見た目としては、一枚目の図の左上のようなボタンを作成します。
実際の手順
Tampermonkeyのインストール
Tampermonkeyは各ブラウザの拡張機能として存在しています。 それをインストールしましょう。
Tampermonkeyでスクリプトを書く
Tampermonkeyのダッシュボードに行きましょう。 そうすると、タブの真ん中に「+」ボタンがあると思うので、そこを押してもらうと以下の画面に遷移すると思います。

ここにユーザスクリプトを書いていきます。 上のheader部分には、Tampermonkeyの設定を書く部分があります。ここには、ユーザスクリプトの実行する条件や環境を書く部分になります。 documentに様々なオプションが挙げられています。
後半部分が実際に実行されるスクリプトになります。 ここにJavaScriptを記述していきます。
今回は、https://www.slideshare.net/にアクセスした際に実行を行いたいので、@matchを用います。
@matchでは、ワイルドカードを使うことができhttps://www.slideshare.net/*と設定することで、slideshareにアクセスした際スクリプトを実行されるようにできます。
ヘッダー部分は以下のようになります。(3分クッキング方式)
// ==UserScript== // @name slideshare button // @namespace http://tampermonkey.net/ // @version 0.1 // @description try to take over the world! // @author You // @match https://www.slideshare.net/* // @grant none // ==/UserScript==
ユーザスクリプトを書く
サイトにアクセスした際に、埋め込みリンクを得てそのリンクへのボタンを生やしましょう。
slideshareでは、実はヘッダー部分のmetaタグのうち、name=twitter:playerに埋め込みリンクがあります。
このタグをquery selecterで取ってきて、ボタンを作成していきます。 ボタンが最上部に出るようにstyleも指定します。
最終的にできるユーザスクリプトは、以下のようになります。
// ==UserScript==
// @name slideshare button
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match https://www.slideshare.net/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const getMeta = document.head.querySelector("[name='twitter:player'][content]").content;
const button = document.createElement("button")
const content = document.createElement("a")
content.setAttribute("href", getMeta)
const textContent = document.createTextNode("埋め込みリンク")
content.appendChild(textContent)
button.appendChild(content)
button.setAttribute("style", "z-index:1; position:fixed; top:0; left:0;")
document.body.appendChild(button)
})();
さて、保存し実際にアクセスすると、ボタンが表示されていると思います。
おわりに
いかかでしたか。
Tampermonkeyには自分のユーザスクリプトを公開する機能、他人のユーザスクリプトを使用する機能があります。 私は、keymoonさんが作成しているAtcoderのac-predicterをインストールし使用しています。
RPythonとPyPyとJITについてのメモ
始めに
これはインターネットアーカイブのためのメモです。
中身
Pythonのインタプリタ by Pythonを記述する。 そうすると、RPythonのプログラムが書けるようになる。 RPythonでPythonインタプリタを作成することができる。 できたものは、「RPythonによるPythonインタプリタ……で、それはPythonで書かれている」ということになる。これ全体をFという関数とする。 そうすると、Fに対してPythonコードとinputを持ってくれば実行ができる。
ここもう少し一般化して、RPythonのインタプリタ by Pythonの役割を考える。
例えば、RPythonによるhoge言語インタプリタを持ってくるとする。 そうすると、RPythonのインタプリタ by Pythonに対して、RPythonによるhoge言語インタプリタと、hoge言語プログラム、inputを以てくれば、outputが得られる。 ここで関数の部分適用を考える。 つまり、RPythonのインタプリタ by Pythonに対して、RPythonによるhoge言語インタプリタを与えた状態を考える。 残り必要なのは、hoge言語プログラムとinputであり、これはちょうどコンパイラの動作と同じである。 (コンパイラも、hoge言語プログラムを与えてできたものに、入力を与えれば実行される。) つまり、RPythonのインタプリタ by Pythonというのはインタプリタ by RPythonを与えれば、コンパイラを生成してくれる何かになる。 ただ、実際はRPythonのインタプリタ by Pythonというのは、hoge言語プログラムだけ部分適用みたいなことをできないので、実際はインタプリタ生成みたいなものである。
PyPyとJITの話に移る。 Python処理系をRPythonで記述することを考える。(これがPyPyの実態ともいえる?) RPythonで書かれた処理系のプログラムは、順番にPythonプログラムと入力をちょっとずつ受け取って評価するみたいな処理になるはずである。 ここでRPythonのインタプリタ by Pythonが役に立つ。RPythonのインタプリタ by Pythonに対して、JITコンパイルの機能を与える。そうすると、Python処理系をRPythonで記述し、RPythonのインタプリタ by Python上で動かせば自動的にJITコンパイルの機能が備わることになる。 (RPythonのインタプリタ by Pythonにとっては、RPythonプログラムと入力としか見えない。) これの何がうれしいかというと、 PythonのJITコンパイルを考える必要がなくなりRPythonのJITをすればよい。 RPythonはどこででも動く。 処理系を書く側はRPythonでインタプリタを書けば自動的にJITコンパイルの機能を持てる。 ということがある。
まとめ
PyPyは、RPythonで書かれたPython処理系だよ。 RPythonはPythonのsubsetでインタプリタを記述する言語であり、RPythonの処理系にはJITの機能があるよ。
参考
これが良い。 Motivating JIT Compiler Generation — RPython Documentation
これもよい。 Partial Evaluation, Futamura Projection And Their Applications · GitHub
これは図がよくわからない。 RPythonについて軽く | κeenのHappy Hacκing Blog
Github Education申請の学生証のアップロードで詰まったときの対処方法
概要
症状
Github Educationで学生証アップロードで画像をアップロードしても、同じページが再度表示され、目に見えるエラーが出てこない。
対処方法
(ページに書かれている基準内であっても、)画像サイズが大きいため、はじかれている可能性がある。 基準ギリギリまで画像サイズを小さくすることによって申請ができる場合がある。
経緯
Github Educationにて、「Please upload proof of your academic status」と書かれ、学生証のアップロードが求められる。 その際、適切に画像ファイルは選択できるが、いざSubmitボタンを押すと同じ画面に戻ってくる。この際、画面には特にエラーが出てこない。
開発者コンソール->Networkで、Preserve logをオンにして見てみると、POST通信でPayload too largeとはじかれていることがわかる。 これを調べると、同様に Payload too largeで困っている人 が見つかり、画像サイズが大きいとだめらしい。
今は確認できないが、そのページに書かれている最大サイズは1.2MBとかでそれを満たしていたはずだが、もう少しぎりぎりまで画像サイズを落とす必要がある。 実際に、画像サイズとその画素をぎりぎりまで落とすと申請ができたので、たぶんこれが原因で合っている。
Ubuntuに入れたNVIDIA driverのupdate
はじめに
update前の環境は以下の通り。
問題
本当は次のようにしたかったが不可能だった。
- 「ソフトウェアのアップデート」というUbuntuのアプリ->追加のドライバーで新しいドライバを選択
- 再起動
したがって、とりあえず追加のドライバーをaptでinstallしてみたが次のエラーで無理だった。
問題を解決することができません。壊れた変更禁止パッケージがあります。
解決
aptitudeに任せた。 するといくつかのパッケージ(cudaを含む)を削除して、driverをアップデートしてくれる。
再起動後、確認すると、aptitude先生によってversion 10.1のCUDA Toolkitが入れられたので、apt remove cuda-toolkitを行い、適切なバージョンのCUDAを適切な手順でインストールした。
今考えると、cuda-toolkitについては、removeとやるよりpurgeしたほうがよかったかもしれない。おそらくこれの影響でCUDAを入れなおしたらPATHを手動で通す必要があった。
今から予想する原因
おそらくもともとの環境にcuda-11-8をinstallしており、それがNVIDIA driverに依存しているから上のエラーを出していたのだと思う。
おそらく適切な手順は、
- CUDAのremove(というかpurge?)
- driverのupdate
と思われる。
NVIDIA driverをUbuntuに入れる
はじめに
NVIDIA driverをUbuntu 20.04 LTSに入れた際の手順です。 備忘録として残します。
手順
- ubuntu-driver devicesによる必要なdriverを確認とinstall
- open, serverなしの無印版を選択
- Nouveauの削除
- 適切に行う。OS起動のconfigに何かを記述した。
- reboot
cudaのinstall
適切なバージョンのcudaを見る。
今回は、localで入れた。
基本はそのままでよいが、最終行だけsudo apt-get install cuda-xx-xと変更し、正しいcuda versionが入るかを確認。
おわり
たぶん以上で行けたはず。
Windowsで自動でssh再接続~Bitvise SSH Clientを用いる~
はじめに
自宅にWindows PCがあり、Windows PCへ接続するためにssh ポートフォワーディングを用いて、踏み台サーバ経由で外出先からsshしています。
Ubuntuであれば、autosshコマンドを用いて、sshが切れた際に自動的に再接続させることが簡単にできます。 Windows PCで同じことをやりたいということで行ったことの備忘録です。
取りうる選択肢
次のことを行えば、自動で再接続させることができると思います。
今回は2番目のBitvise SSH Clientを用いる方法で行きます。 個人的にはこれが簡単だと思います。
Bitvise SSH ClientでSSHを行う
Bitvise SSH Clientのインストール
Bitvise SSH Clientのダウンロードページに行き、SSH Clientをダウンロード、インストールします。
ここは難しいことはないと思います。
Bitvise SSH clientでSSH接続する
今回は、SSH keyで接続する方法を説明します。
鍵を作る
まず、起動しLoginタブのClient key managerを開きます。
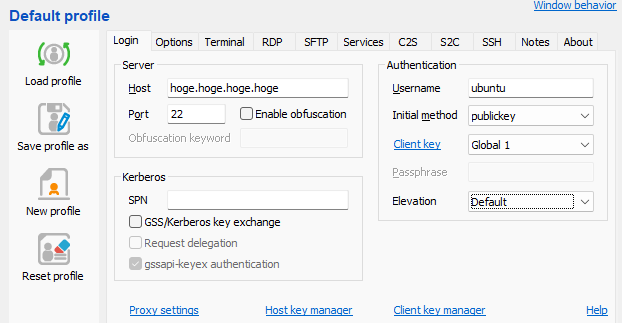
ここで、下のほうにGenerate newというボタンがあると思うので、そこを押し、いい感じに設定し鍵を作ります。
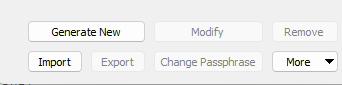
鍵を作ると、先ほどのClient key manager上で作成した鍵が表れていると思います。それを選択し、Exportと押すと、Public keyを得ることができます。 それをサーバに登録します。
SSHする
先ほどのLoginタブに戻り、いい感じにServerとAuthenticationの欄を埋めます。 この状態で、Log inとするとSSHすることができます。
この状態でもうサーバが一時的にダウンしたとしても自動的に再接続される状態になっていると思います。
Port forwardingする
サーバ側の3389番ポートへの通信を、Windows PCの3389番ポートへ転送します。 この場合は、S2Cのタブを開き次のように設定します。
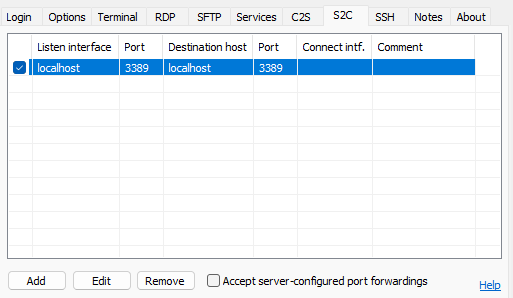
これでLog inすると、ポートフォワードができると思います。
PC起動時に自動的にSSH接続するようにする
プロファイルを保存する
左側のSave Profile Asで適当な場所に、clientの設定を保存します。
コマンドからClientを起動する
コマンドからClientを起動させることができます。 具体的には次のようになると思います。
BvSsh.exe -profile=C:\Path\to\hoge.bscp -loginOnStartup
これでバックでClientが立ち上がり、SSH loginした状態になると思います。
スタートアップに登録する
先ほどのコマンドをWindowsのスタートアップに登録します。 こうすることで、Windowsの起動時に自動的にClientが立ち上がりサーバに接続されます。 サービスとして登録するほうが正統らしいですが、いまのところこれで十分なのでokです。
おそらくスタートアップに登録する方法はいろいろあると思いますが、自分はショートカットを作成しました。
Windows+Rでshell:startupを実行します。

そうすると、ファイルエクスプローラが起動するので、そこにBitvise SSH Clientのショートカットを作成します。 自分の環境では、リンク先として次を指定しました。
"C:\Program Files (x86)\Bitvise SSH Client\BvSsh.exe" -profile=C:\Path\to\hoge.bscp -loginOnStartup
この状態でタスクマネージャのスタートアップアプリを見ると、BvSsH.exeみたいにBitvise SSH Clientが登録されています。
以上で、外出する際は、PCの電源ボタンを入れていくだけでSSHされた状態になります。
おわりに
参考になれば幸いです。
参考文献
https://laubit.blogspot.com/2017/01/putty.html https://www.mazn.net/2020/10/2085.html https://yohei-a.hatenablog.jp/entry/20140902/1409629766 https://www.kmc.gr.jp/advent-calendar/ssh/2013/12/11/autossh.html#fn:bitvise